TACO Logging
by 임성일(si.im@sk.com)
Update on 2019.07.30 새로운 블로그로 이전하였습니다
Overview
실행 중인 애플리케이션이나 시스템의 내부 상황을 파악하는데 일반적으로 로그를 사용합니다. 특히, 로그는 문제를 디버깅하고 작업을 모니터링하는 데 유용합니다. 일반적인 응용 소프트웨어들은 다양한 로깅 메커니즘을 제공하고 있으며 TACO의 기반 소프트웨어인 오픈소스들도 각각의 로깅 기능을 제공합니다. TACO의 기반 컨테이너 엔진인 docker-engine의 경우 간단하면서 일반적으로 사용하는 logging 방식인 표준출력과 표준에러를 사용하는 로깅 기능을 제공하고 있습니다. 차상위 시스템인 kubernetes 또한 그 나름의 로깅 기능을 제공합니다.
하지만 docker나 kubernetes에서 제공하는 로깅 기능으로는 TACO의 상황을 효율적으로 감시할 수 없습니다. TACO의 로그는 그 구성요소인 pod나 컨테이너등의 문제로 인해 재기동 되거나 삭제 되었을때에도 관련 로그를 유지하고 있어야 하며 이를 위해 별도의 저장소와 유지주기 등을 관리해야 합니다. 이러한 기능을 수행하는 것을 TACO Logging 입니다.
본 포스트에서는 TACO Logging의 구조와 동작방식을 설명하여 독자들의 이해도를 높히고자 합니다. 또한, 사용자의 요구사항을 반영하는 변경을 구축에 반영하는 예시를 제시하여 이를 참조하여 자신만의 구축형상을 수정할 수 있도록 하겠습니다.
Logging in docker
TACO의 기반 컨테이너 엔진인 docker는 자체의 로깅 기능을 제공하고 있습니다. 로깅 드라이버(logging driver)를 사용하여 표준출력과 표준에러에 대한 처리를 수행합니다. 기본설정에서 docker는 표준출력과 표준에러애서 발생하는 모든 로그를 json 형태로 변환하여 각 컨테이너별 로그파일로 저장합니다. 로깅 드라이버는 컨테이너마다 지정할 수 있으며 이에 대한 설정등은 다음의 페이지를 참조할 수 있습니다.
- 로깅 드라이버 설정 (https://docs.docker.com/config/containers/logging/configure/)
- 드라이버에 plugin 적용 (https://docs.docker.com/config/containers/logging/plugins/)
- output 조절하기 (https://docs.docker.com/config/containers/logging/log_tags/)
Logging in kubernetes
Kubernetes에서는 App과 system의 log를 제공하여 클러스터 내부를 사용자가 이해할수 있도록 돕습니다. 간단하게 다음과 같은 명령으로 클러스터내 존재하는 POD (컨테이너)에 대한 로그를 얻어올 수 있습니다.
kubectl logs -n [namespace] [pod_name]
taco@master:~$ kubectl logs elasticsearch-data-2
+ COMMAND=start
+ start
+ ulimit -l unlimited
+ exec /docker-entrypoint.sh elasticsearch
[2018-04-13T05:07:27,992][INFO ][o.e.n.Node ] [elasticsearch-data-2] initializing ...
[2018-04-13T05:07:28,193][INFO ][o.e.e.NodeEnvironment ] [elasticsearch-data-2] using [1] data paths, mounts [[/usr/share/elasticsearch/data (/dev/rbd4)]], net usable_space [933.2gb], net total_space [984.1gb], spins? [no], types [ext4]
[2018-04-13T05:07:28,194][INFO ][o.e.e.NodeEnvironment ] [elasticsearch-data-2] heap size [1.9gb], compressed ordinary object pointers [true]
[2018-04-13T05:07:28,298][INFO ][o.e.n.Node ] [elasticsearch-data-2] node name [elasticsearch-data-2], node ID [-B45XC7NR5qqvab3zfqgdg]
[2018-04-13T05:07:28,298][INFO ][o.e.n.Node ] [elasticsearch-data-2] version[5.6.4], pid[41], build[8bbedf5/2017-10-31T18:55:38.105Z], OS[Linux/4.4.0-116-generic/amd64], JVM[Oracle Corporation/OpenJDK 64-Bit Server VM/1.8.0_151/25.151-b12]
[2018-04-13T05:07:28,298][INFO ][o.e.n.Node ] [elasticsearch-data-2] JVM arguments [-Xms2g, -Xmx2g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -Djdk.io.permissionsUseCanonicalPath=true, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Dlog4j.skipJansi=true, -XX:+HeapDumpOnOutOfMemoryError, -Xms2g, -Xmx2g, -Des.path.home=/usr/share/elasticsearch]
[2018-04-13T05:07:29,169][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [aggs-matrix-stats]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [ingest-common]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [lang-expression]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [lang-groovy]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [lang-mustache]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [lang-painless]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [parent-join]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [percolator]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [reindex]
[2018-04-13T05:07:29,170][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [transport-netty3]
[2018-04-13T05:07:29,171][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] loaded module [transport-netty4]
[2018-04-13T05:07:29,171][INFO ][o.e.p.PluginsService ] [elasticsearch-data-2] no plugins loaded
[2018-04-13T05:07:30,393][INFO ][o.e.d.DiscoveryModule ] [elasticsearch-data-2] using discovery type [zen]
[2018-04-13T05:07:31,121][INFO ][o.e.n.Node ] [elasticsearch-data-2] initialized
[2018-04-13T05:07:31,121][INFO ][o.e.n.Node ] [elasticsearch-data-2] starting ...
[2018-04-13T05:07:31,274][INFO ][o.e.t.TransportService ] [elasticsearch-data-2] publish_address {172.16.119.179:9300}, bound_addresses {[::]:9300}
[2018-04-13T05:07:31,283][INFO ][o.e.b.BootstrapChecks ] [elasticsearch-data-2] bound or publishing to a non-loopback or non-link-local address, enforcing bootstrap checks
그림출처: https://kubernetes.io
kubernetes는 노드수준에서 로그의 보존, 로테이션 기능을 제공합니다. 또한 POD의 타 노드로 이동(migraion)시 컨테이너 뿐 아니라 해당 로그를 함께 옮겨주는 기능도 수행하고 있습니다. 노드수준에서의 로깅기능만 제공하고 있을뿐 공식적으로 클러스터 수준에서 로깅기능을 제공하는 솔루션은 없습니다.
fluent-logging (Central logging on k8s)
Cluster logging in k8s (reference architecture)
kubernetes에서는 공식적인 솔루션을 제시하지 않지만 다음과 같은 일반적인 방식을 고려할 수 있습니다.
- Use a node-level logging agent that runs on every node. (fluent-logging approach)
- Include a dedicated sidecar container for logging in an application pod.
- Push logs directly to a backend from within an application.
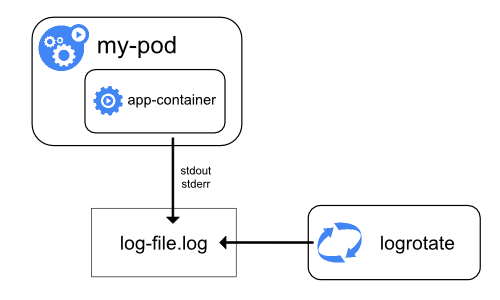
공식 페이지에서는 아래와 같은 아키텍쳐를 제시합니다.(kubernetes logging)
| Using a node logging agent | Streaming sidecar container |
|---|---|
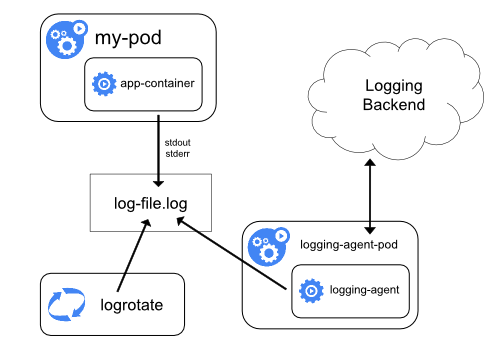 |
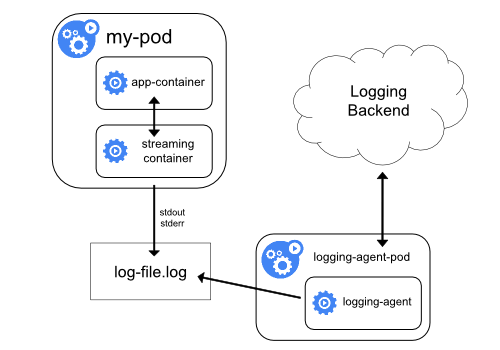 |
| Sidecar container with a logging agent | Exposing logs directly from the application |
|---|---|
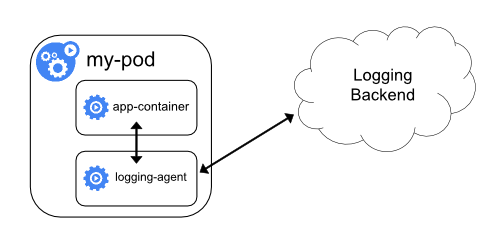 |
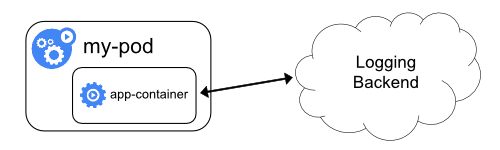 |
그림출처: https://kubernetes.io
Architecture
앞에서 언급한 것처럼 kubernetes는 몇가지 클러스터 수준의 로깅기능을 제시하고 있습니다. 제시된 모델 중 첫번째 방식(Using a node logging agent)를 제외한 나머지 방법은 해당 애플리케이션(POD) 내부에 해당 기능을 제공해야 합니다. 이에 따라, 우리는 기존 애플리케이션의 변경없이 사용할 수 있는 logging agent를 사용하는 방법을 사용하였고 기반시스템에서 제공하는 로깅기능을 활용하여 필요한 메타정보를 추가하여 별도 저장하는 형태로 시스템을 설계했습니다. 또한 agent 설치 노드에 대한 small-footprint를 유지하도록 하면서 확장성을 확보하도록 하는 유연한 구조를 갖도록 하였습니다.
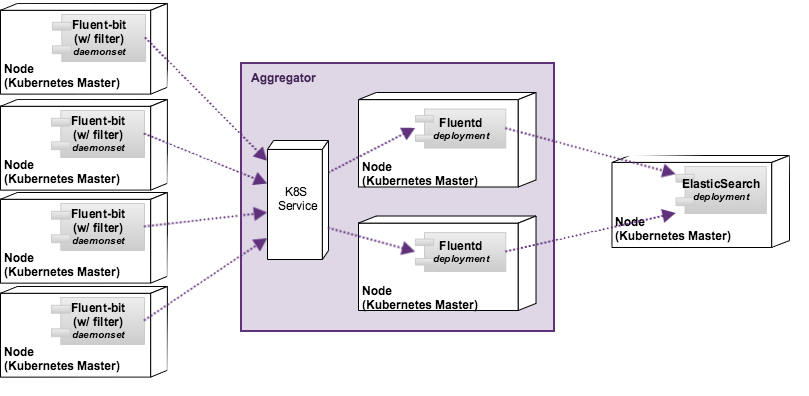
- log collection:
- 해당 노드에서 동작 중인 컨테이너의 로그를 수집하고 이를 aggregator에 전달
- Small-footprint 유지
- 각 물리노드 별로 daemonset으로 기동
- fluent-bit 사용
- aggregator
- 수집된 로그에 필요한 전/후처리 가능하고 다양하게 확장가능
- 지정한 노드에 필요한 수 만큼의 deployment로 기동
- fluentd 사용
- storage
- 수집된 로그를 저장하고 조회기능 제공
- 필요한 크기에 따라 저장/조회/정보저장용 pod 각각 조정가능
- elasticsearch 사용(JVM Heap사이즈 조정 및 디스크 용량만 변경하여 최적화)
- Presentation Layer
- 데이터에 대한 조회 및 통계를 위한 사용자 인터페이스 제공
- 정형화된 조회구조를 정의 후 대시보드 구성
- kibana 사용
추가적으로 TACO Logging은 3rd-party 툴 연동이 가능합니다. 통합기(aggregator)를 통해 kafka에 데이터를 전달할 수 있도록 구현되어 있으며 외부 툴들은 kafka의 데이터를 구독하면 TACO Logging에서 수집한 로그를 실시간 활용가능합니다.
참고. Agent 선택
오픈소스 진영에는 logstash, fluentd, flume, beaver와 같이 다양한 로그수집기가 존재한다. 이들은 각각의 특징을 갖고 있으며 이에 따라 상황에 따른 장단점을 갖고 있다. 일반적인 경우에 logstash가 가장 많이 쓰이고 있으며, Hadoop 등 Big-Data 관련 솔루션의 경우 flume을 선호하는 경향이 있다. Monasca 진영의 경우 beaver를 사용하여 로그를 수집한다. 그 외에도 elasticsearch 등을 주도하고 있는 elastic.co의 filebeat 또한 고려가능하다. TACO에서는 kubernetes의 매타정보를 가장 잘 반영할 수 있고 fluent-bit으로 small-footprint를 지원하는 fluent를 수집기로 선정하여 사용하였다.
Fluent 진영에서는 small-footprint 지원을 위해 기존의 로그 수집기인 fluentd와 별도로 이를 경량화한 fluent-bit이라는 로그수집기를 소개하였으며 두 수집기의 차이는 아래 표와 같다. TACO에서는 이러한 특징을 반영하여 로그 수집기로 fluent-bit을 로그 통합기(aggregator)로 fluentd를 사용하였다.
| Fluentd | Fluent Bit | |
|---|---|---|
| Scope | Containers / Servers | Containers / Servers |
| Language | C & Ruby | C |
| Memory | ~40MB | ~450KB |
| Performance | High Performance | High Performance |
| Dependencies | Built as a Ruby Gem, it requires a certain number of gems. | Zero dependencies, unless some special plugin requires them. |
| Plugins | More than 650 plugins available | Around 30 plugins available |
| License | Apache License v2.0 | Apache License v2.0 |
| memo | Various plugins | Small foot-print |
참고. 노드별 로그위치
docker의 경우 기본적으로 모든 컨테이너 로그를 물리서버(BareMetal)의 /var/lib/docker/containers/[Container-HASH]/[Container-HASH]-[Type].log 의 위치에 type별 로그를 저장한다. k8s에서는 이 로그를 필요한 매타데이터와 함께 link를 설정하여 각 로그파일을 관리한다. k8s의 관점에서 보면 모든 pod의 로그들을 /var/log/container/* 형태로 하나의 디렉토리 하부에 매타정보를 포함한 링크명과 함께 저장하여 관리하고 있다. TACO에서 설치하는 로그 수집기는 해당 디렉토리에서 발생하는 모든 로그를 추적하는 것으로 raw 데이터를 수집하고 필요한 매타정보를 추가하여 저장소로 전달한다.
링크로 연결된 로그파일 예시
/var/log/containers/weave-scope-app-65f7f776f9-b6qkk_kube-system_app-eccff309fe566b5397faa3939cfa2773966f9a39e3bf0b3f598f45c94f80e13f.log -> /var/log/pods/8de1b0c2-062d-11e8-b54c-3ca82a1c8f58/app_0.log
/var/log/pods/8de1b0c2-062d-11e8-b54c-3ca82a1c8f58/app_0.log -> /var/lib/docker/containers/eccff309fe566b5397faa3939cfa2773966f9a39e3bf0b3f598f45c94f80e13f/eccff309fe566b5397faa3939cfa2773966f9a39e3bf0b3f598f45c94f80e13f-json.log
/var/lib/docker/containers/eccff309fe566b5397faa3939cfa2773966f9a39e3bf0b3f598f45c94f80e13f/eccff309fe566b5397faa3939cfa2773966f9a39e3bf0b3f598f45c94f80e13f-json.log
Logs in ElasticSearch (Schema)
TACO에서 수집된 로그는 최종 저장소인 ElasticSearch(이하 ES)에 다양한 메타정보를 포함하여 저장됩니다. 저장되는 단위는 표준출력 혹은 표준에러에서 발생하는 로그 한줄이 하나의 도큐먼트화되어 저장됩니다. 저장된 데이터를 효율적으로 활용하기 위해서는 저장형태에 대한 규정이 필요합니다. fluent-logging은 이를 위해 ES의 대상 인덱스에 mapping (스키마)를 설정하고 있습니다. 이 값은 구축시 사용자의 요구에 따라 변경 가능합니다.
기본적으로 ES는 모든 문장을 단어단위로 분리하여 저장합니다. 추후 조회나 분류를 위해 정확한 필드의 내용을 사용해야 하는 경우 분리된(tokenized) 필드의 경우 해당 작업이 힘들거나 불가능 할 수도 있습니다. 예를들면 pod명의 경우 ‘weave-scope-agent-56dfr’ 와 같은 값을 갖는데 기본 저장방식을 사용하면 weave, scope, agent, 56dfr 형태로 각각 분리되어 저장되고 검색도 단어 단위로 이뤄집니다.
fluent-logging에서는 다음의 정보들을 활용하기 위해 분리하지 않고 키워드 형태로 저장하도록 하고 있으며 인덱스와 저장되는 데이터의 예시는 다음과 같습니다.
Mapping
"mappings" : {
"fluent-logging" : {
"properties" : {
"kubernetes" : {
"properties" : {
"container_name" : {
"index" : "not_analyzed",
"type" : "keyword"
},
"docker_id" : {
"index" : "not_analyzed",
"type" : "keyword"
},
"host" : {
"index" : "not_analyzed",
"type" : "keyword"
},
"labels" : {
"properties" : {
"app" : {
"index" : "not_analyzed",
"type" : "keyword"
},
"application" : {
"index" : "not_analyzed",
"type" : "keyword"
},
"component" : {
"index" : "not_analyzed",
"type" : "keyword"
},
"release_group" : {
"index" : "not_analyzed",
"type" : "keyword"
}
}
},
"namespace_name" : {
"index" : "not_analyzed",
"type" : "keyword"
},
"pod_id" : {
"index" : "not_analyzed",
"type" : "keyword"
},
"pod_name" : {
"index" : "not_analyzed",
"type" : "keyword"
}
}
},
"log" : {
"type" : "text"
}
}
}
}
저장 데이터 예시
{
"_index":"logstash-2018.02.04",
"_type":"fluent-logging",
"_id":"AWFeY7RauuiH0H_zHFxS",
"_version":1,
"_score":1,
"_source":{
"@timestamp":"2018-02-04T01:17:27.349Z",
"log":"\u003cprobe\u003e WARN: 2018/02/04 01:17:27.349408 Cannot obtain local \
pods, reporting all (which may impact performance): Get http://localhost:10255/pods/: \
dial tcp 127.0.0.1:10255: getsockopt: connection refused\n",
"stream":"stderr",
"time":"2018-02-04T01:17:27.349642941Z",
"kubernetes":{
"pod_name":"weave-scope-agent-56dfr",
"namespace_name":"kube-system",
"pod_id":"efe7252d-e565-11e7-b0d2-90e2bab4f938",
"labels":{
"app":"weave-scope",
"controller-revision-hash":"1130764677",
"name":"weave-scope-agent",
"pod-template-generation":"1",
"weave-cloud-component":"scope",
"weave-scope-component":"agent"
},
"annotations":{
"kubernetes_io/created-by":"{\"kind\":\"SerializedReference\",\"apiVersion\":\
\"v1\",\"reference\":{\"kind\":\"DaemonSet\",\"namespace\":\"kube-system\",\"name\":\
\"weave-scope-agent\",\"uid\":\"efb7bba7-e565-11e7-b0d2-90e2bab4f938\",\"apiVersion\":\
\"extensions\",\"resourceVersion\":\"948\"}}\n"
},
"host":"k2-node06",
"container_name":"agent",
"docker_id":"fe76859161a19a151e3dbec93db96231b9768452b818f3731f390a7985f4b003"
}
}
}
ES의 다양한 기능을 사용하면 저장된 데이터에 대한 검색을 통해 원하는 로그를 찾아낼수 있고 필요한 통계의 추출도 가능합니다. ES는 인덱스, 타입, 필드 순의 자료구조를 갖고 있으며 필드에 구체적인 값을 저장합니다. 앞에 정의한 mapping(스키마)에서 각각 필드에 대한 속성을 정의하고 있으며 정의된 속성에 따라 가능한 검색기능이 제한됩니다.
TACO Logging에서 저장하는 로그데이터에서 중요성을 갖는 필드들은 다음과 같습니다. 필드별 의미는 명칭에서 충분히 설명하고 있습니다. 해당필드를 사용하여 데이터를 검색하고 통계정보를 생성하면 수집된 로그에 대한 insight를 얻어낼 수 있습니다.
- kubernetes.namespace_name
- kubernetes.pod_name
- kubernetes.pod_id
- kubernetes.host
- kubernetes.container_name
- kubernetes.docker_id
- kubernetes.label
- app
- application
- component
- release_group
Fluent-logging chart
TACO Logging을 구현하기위해 fluent-logging chart가 TACO팀 주도로 개발되었으며 앞의 Architecture 부분에서 언급한 것처럼 fluent, elasticsearch, kibana를 사용하도록 구현되었습니다. openstack-helm-infra에는 fluent-logging 외 ElasticSearch와 Kibana 차트도 제공되고 있으며 TACO 역시 해당 프로젝트에서 제공하는 챠트들을 사용하여 구축합니다.
사용자의 필요에 의해 기 구축된 ElasticSearch 사용하거나 다른 저장소의 사용 또한 가능합니다.
Customization
TACO Logging은 Kubernetes의 Helm 차트를 사용하여 배포합니다. Helm의 value-override 기능을 사용하면 구축시 필요한 다양한 요구사항을 변형할 수 있습니다. TACO Logging를 구성하는 ElasticSearch, Fluent-bit, Fluentd의 설정은 value-override 기능을 통해 재지정 가능합니다. 본 절에서는 몇가지 유용한 변경 예시를 살펴보고 간단한 설명을 통해 사용자가 필요한 요구조건을 반영하기위해 어떤 값을 변경시켜나갈 것인지에 대한 방법을 제시하고자 합니다.
간결한 구조 예시 (Fluent-bit/ElasticSearch)
현재 kubernetes에 대한 메타정보는 Fluent-bit의 plugin을 통해 입력되고 있습니다. 따라서 별다른 전/후처리가 필요하지 않다면 중간의 aggregation 단계를 생략하고 로그자체를 Fluent-bit -> ElasticSearch 로 전달하는 2단계 구성이 가능해 집니다. 이를 통해 만들어지는 EFK 구조를 도식화 하면 다음과 같습니다.
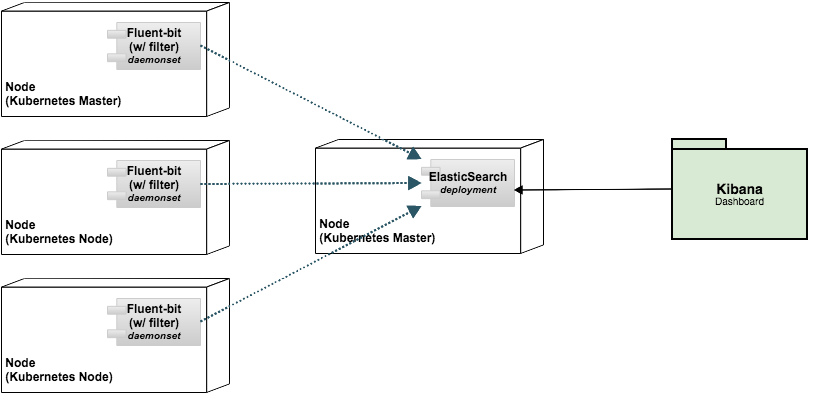
fluent-logging의 value.yaml은 conf 필드에 개별 설정파일을 정의하고 있습니다. fluentbit의 설정은 conf.fluentbit 필드에서 정의하고 있으며 Fluentbit 설정을 참조하여 다음과 같이 변경하면 output을 ElasticSearch로 설정함으로써 위 구조를 적용시킬수 있습니다. (es_output)
conf:
fluentbit:
- service:
header: service
Flush: 1
Daemon: Off
Log_Level: info
Parsers_File: parsers.conf
- containers_tail:
header: input
Name: tail
Tag: kube.*
Path: /var/log/containers/*.log
Parser: docker
DB: /var/log/flb_kube.db
Mem_Buf_Limit: 5MB
- kube_filter:
header: filter
Name: kubernetes
Match: kube.*
Merge_JSON_Log: On
- es_output:
header: output
Name: es
Match: "*"
Host: elasticsearch-logging
Port: 80
Logstash_Format: On
HTTP_User: "admin"
HTTP_Passwd: "changeme"
Federation을 위한 구축 예시
Fluent-logging은 기본적으로 해당 클러스터에서 발생하는 로그에 대한 수용합니다. 따라서 모든 수집된 로그는 동일한 클러스터에서 발생된 것을 가정하고 있습니다. 경우에따라 다수의 클러스터에서 발생하는 로그를 하나의 TACO Logging에 수용하고 관리해야하는 경우 Federation 기능이 필요합니다. 이러한 구조는 다음과 같이 도식화 할수 있습니다.
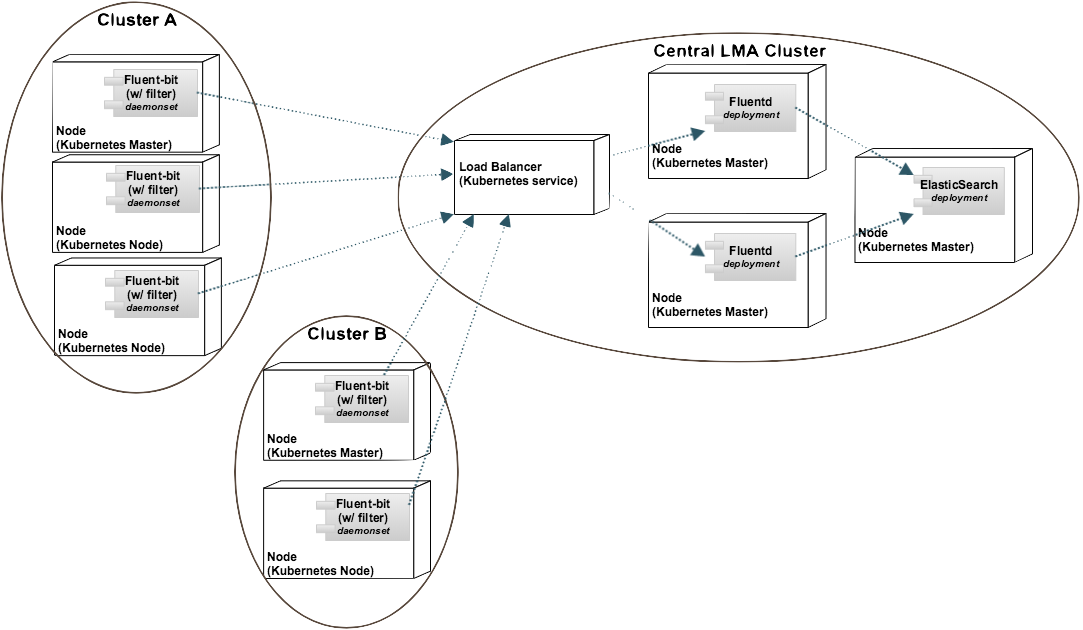
다수의 클러스터에서 수집되는 로그들을 하나의 저장소에 보관하고 이를 구분하여 처리하기 위해서는 수집되는 클러스터의 명칭을 정의하는 것이 필요합니다. fluent-bit의 필터 중 record_modifier 필터는 원하는 매타정보를 추가하는 기능을 제공하고 있으며 이를 활용하여 수집클러스터를 표기하도록 합니다.
- cluster_filter:
header: filter
Name: record_modifier
Match: "*"
record: cluster /* 클러스터 정보 ex> client */
Federation을 위해 클러스터간 데이터 전달이 필요한데 이를위해 aggregator를 사용하면 다음과 같이 구성이 됩니다. 저장소가 위치한 클러스터(상단 그림의 Central LMA Cluster)의 aggregator의 노드포트를 설정합니다. (노드포트는 k8s에서 물리노드의 포트를 내부의 자원에서 사용할 수 있도록 하는 요소)
network:
fluentd:
node_port:
enabled: true
port: 32323
로그를 수집하여 전달하고자하는 클러스터(상단 그림의 Cluster A/B)의 로그수집기는 앞에서 열려진 노드포트로 로그를 전달하도록 변경합니다.
- fluentd_output:
header: output
Name: forward
Match: "*"
Host: /* 서버 ex> 192.168.48.202*/
Port: /* 포트넘버 ex> 32323 */
Conclusion
본 포스트에서는 TACO에서 제공하는 Logging mechanism과 주변 기술들에 대해 상세히 기술하였습니다. 또한 환경에 따른 변경 가능성을 몇가지 예시를 통해 제시하였습니다. TACO Logging은 kubernetes 클러스터 로깅 서비스로서 kubernetes에 올라가는 서비스라면 TACO외의 다른 서비스에서도 사용 가능합니다. 이후 개발방향은 Prometheus의 AlertManager 기능 연계를 통해 수집된 로그로부터 알람을 발생시키는 기능, 다양한 로그파일을 수집하는 기능 등이 추가될 예정입니다. 관심이 있는 분들은 Openstack Review나 Virtualization Software Lab.의 github를 통해 협업 가능합니다.