Prometheus를 이용한 Event Alerting in TACO
by 최태일(taeil.choi@sk.com)
Update on 2019.07.30 새로운 블로그로 이전하였습니다
Overview
이번 포스팅에서는 Kubernetes 환경에서 모니터링 tool로 많이 사용되고 있는 Prometheus를 사용하여 TACO 서비스에 이벤트 발생시 Alerting해주는 부분에 대해 살펴보겠습니다. 실제 TACO에서 사용 중인 Event alerting 내용을 보여드리기보다는, 독자들의 이해를 돕기 위해 Metric 수집부터 실제 Alert notification까지의 기본적인 Flow를 Tutorial 형식으로 풀어나가려고 합니다.
Prometheus 개요
Prometheus는 시계열 데이터 모니터링을 수행하는 오픈소스 모니터링 솔루션입니다. 음악 유통 플랫폼 회사인 SoundCloud라는 곳에서 시작한 프로젝트이고, 2012년 이후 여러회사에서 참여해서 발전하다가 2016년도에 Cloud Native Computing Foundation에 합류하였습니다. Kubernetes에 이은 두번째 공식 프로젝트이죠.
Go 언어로 개발되었고, Apache License v2.0 을 따르며, 다음과 같은 특징을 가집니다.
- Multi-demensional data model
- 데이터는 초기 버전에서는 key-value 형태의 NoSQL DB인 LevelDB에 저장하였으나 v2.0부터는 자체 TSDB를 개발하여 사용
- 유연하고 사용하기 쉬운 query language
- http 프로토콜을 사용한 server-side pull 방식의 시계열데이터 수집
- Service Discovery나 Static 모두 사용가능한 구조
Prometheus Architecture는 다음과 같습니다.
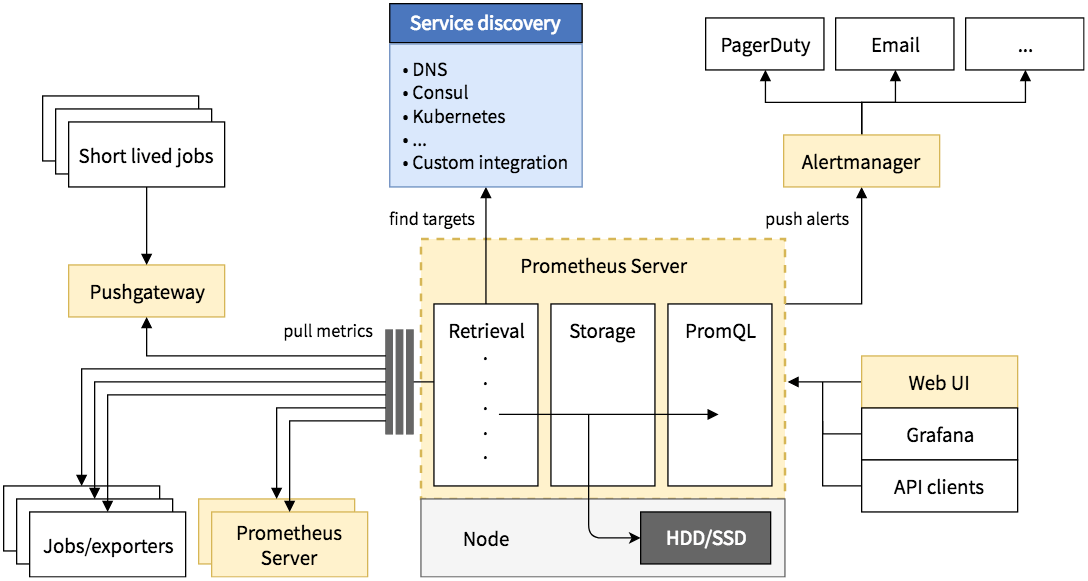
기본적으로 exporter 들로부터 pull 방식으로 metric을 가져오며 Service Discovery 기능을 통해 Kubernetes 클러스터 등 외부 Resource들에 대한 metric도 가져오게 됩니다. 발생한 Alert은 alertmanager에게 전달하여 email이나 slack 등의 receiver로 alert 메세지를 발송합니다.
Step by Step Guide for Alerting
prometheus 및 node-exporter 실행
아래 가이드에 따라 prometheus 및 node-exporter를 실행합니다. (이 가이드에서는 두 프로세스 모두 system service로 등록하였지만, 단순히 테스트 목적이라면 그 과정은 생략하고 command를 직접 수행해도 무방합니다.)
https://www.booleanworld.com/install-use-prometheus-monitoring/
Prometheus 에 Alert Rule 등록
alert을 추가하기 위해서는 alert rule을 등록해야 하는데 과정은 다음과 같습니다.
/etc/prometheus/prometheus.yml 에 사용할 alert rule 파일명을 지정해줍니다.
rule_files:
- "alert.rules"
그리고 alert rule file을 다음과 같이 작성합니다. alert 발생을 쉽게 확인하기 위해 memory 사용량 임계점 수치를 매우 낮게 설정하였습니다.
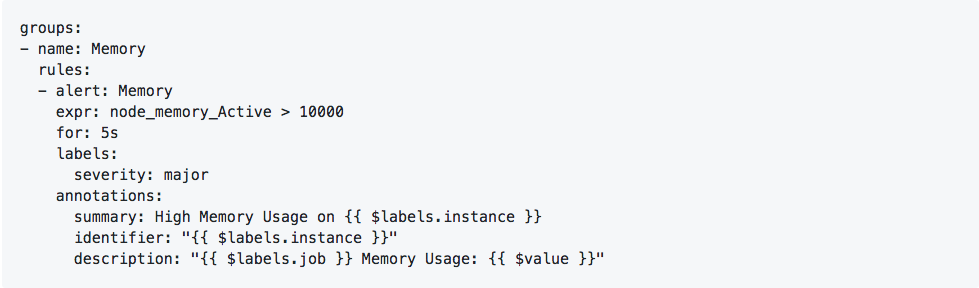
여기서 for 부분에 5s 를 설정한 것은, expr 부분에 명시한 조건이 5초 이상 발생한 경우에 알람을 발생시키겠다는 의미입니다. 일반적으로는 좀 더 길게 설정하지만, 역시 alert 발생을 쉽게 확인하기 위해 테스트 목적으로 짧게 지정하였습니다.
실제 alert message에서는 $labels.instance 는 alert이 발생한 노드명으로 치환되고, $value 는 실제 해당 metric의 값으로 치환됩니다. 이 경우에는 memory 사용량이 들어가게 됩니다.
여기까지 하면 alert이 발생하고, prometheus dashboard 에서 조회할 수 있게 됩니다. 이제 발생된 alert을 적절한 destination으로 notify 해줘야 하는데 그 부분은 alertmanager가 담당하게 됩니다.
AlertManager 설정
AlertManager는 Prometheus 로부터 alert를 전달받아 이를 적절한 포맷으로 가공하여 notify해주는 역할을 합니다.
우선 Alertmanager 를 다운로드 받아 압축을 풉니다. 아래 예시에서는 /root 디렉토리에서 진행하였지만 실제로는 어느 위치라도 무방합니다.
cd /root
wget https://github.com/prometheus/alertmanager/releases/download/v0.15.1/alertmanager-0.15.1.linux-amd64.tar.gz
tar xvf alertmanager-0.15.1.linux-amd64.tar.gz
mv alertmanager-0.15.1.linux-amd64 alertmanager
cd alertmanager
이제 아래와 같이 alertmanager가 사용할 기본 config 파일을 작성합니다.
/root/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
slack_api_url: "https://hooks.slack.com/services/T0WU4JZEX/BC1A8B28K/phzHpkJLzvlc….……..”
route:
group_by: ['alertname']
group_wait: 30s
repeat_interval: 1h
receiver: 'slack-alert'
routes: []
receivers:
- name: 'slack-alert'
slack_configs:
- channel: "#jenkins"
username: "Prometheus"
send_resolved: true
title: ''
text: ''
templates:
- '/root/alertmanager/mytemp.tmpl'
각 항목에 대한 상세설명은 공식 documentation page https://prometheus.io/docs/alerting/configuration/ 를 참조하시면 됩니다.
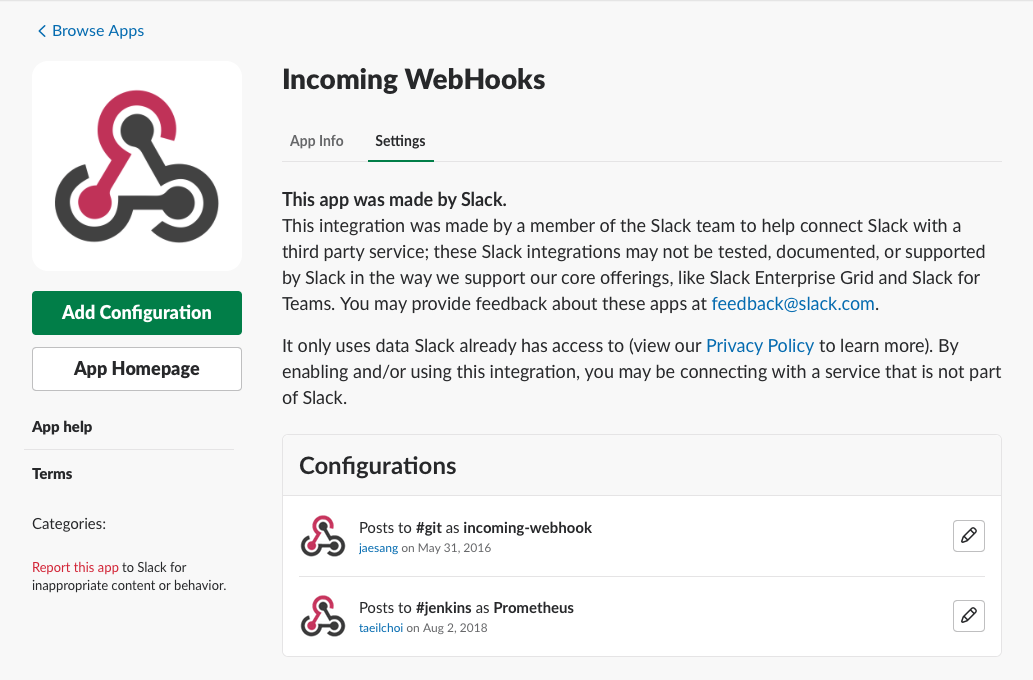
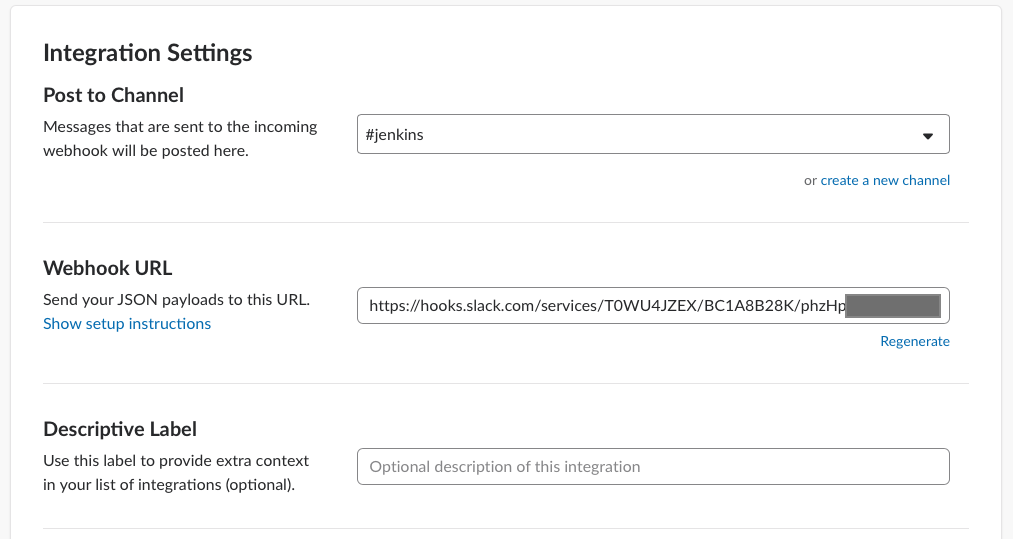
간단히 말씀드리면 여기서는 notify할 대상으로 slack 을 선택하였고, 이를 위해 slack api URL과 slack channel명 등을 넣어주었습니다. Slack api URL은 Slack App에서 다음 메뉴로 들어가면 추가하거나 조회할 수 있습니다.
Administration > Manage apps > Custom Integration > Incoming Webhooks
Route 항목은 alert 성격에 따라 각각 다른 destination 으로 alert을 전송하고자 하는 경우에 routing tree를 구성하여 사용하게 되는데, 여기서는 단일 receiver (slack)만 사용하므로 최상위의 root route만 존재하고 하위 노드들은 [] 로 설정하였습니다.
하단의 template은 notification message 의 포맷을 담고 있는 template file명을 지정합니다. mytemp.tmpl 파일은 다음과 같이 작성하였습니다.
- /root/alertmanager/mytemp.tmpl
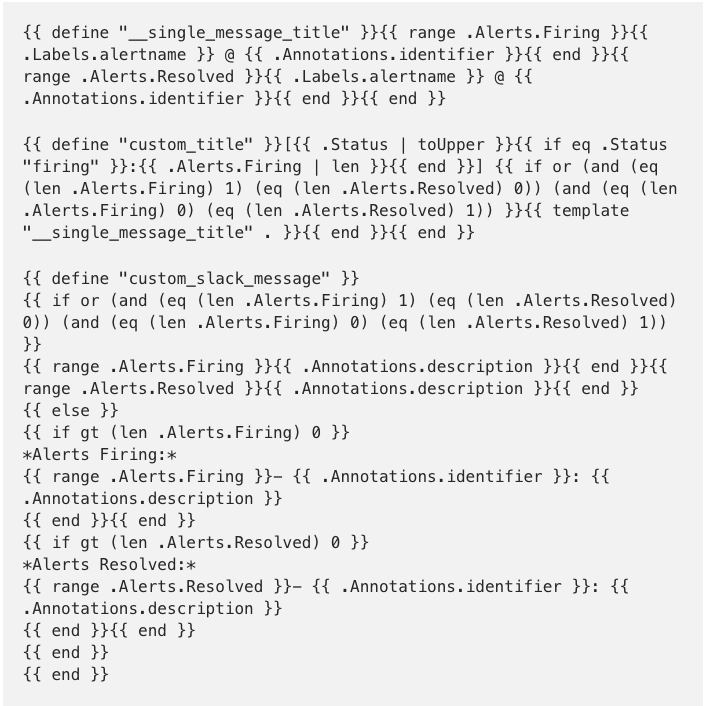
- 출처: https://medium.com/quiq-blog/better-slack-alerts-from-prometheus-49125c8c672b
Golang template 이라 보기가 좀 쉽지는 않지만 간단히 말씀드리면,
- 단일 alert이 발생했을 경우는 아래와 같이 제목 라인에 alert이 발생한 노드 정보가 표시되고 다음 라인에 alert 메세지가 표시됩니다.
- 복수개의 alert이 발생했을 경우는 제목 라인에는 총 alert 갯수만 표시되고, 다음 라인부터는 노드명과 alert 메세지가 함께 표시됩니다.
Alertmanager 실행 및 확인
이제 설정 작업을 마쳤으므로 Alertmanager를 실행합니다.
cd /root/alertmanager
./alertmanager --config.file=alertmanager.yml &
이렇게 등록하면 잠시 후 slack에서 다음과 같은 notification 메세지를 볼 수 있습니다.
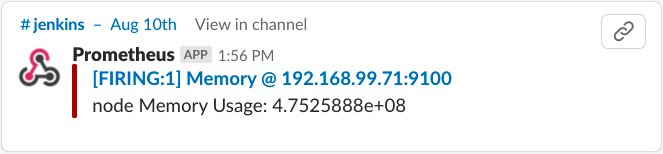
Openstack 커뮤니티의 Default Alert Rules
TACO의 경우 Openstack service 및 Prometheus 등의 monitoring tool들을 다음과 같은 helm chart를 이용하여 배포하고 있습니다.
- https://github.com/openstack/openstack-helm
- https://github.com/openstack/openstack-helm-infra
그 중 prometheus chart를 보면 다음과 같이 수많은 alert rule들이 정의되어 있습니다. SKT도 커뮤니티에 적극적으로 참여하고 있는 만큼, 이 리스트는 커뮤니티 차원에서 계속 발전시켜 나갈 예정입니다.
https://github.com/openstack/openstack-helm-infra/blob/master/prometheus/values.yaml#L797-L1788
맺음말
이번 포스팅에서는 Prometheus를 통해 기본적인 Node Metric을 수집하고 간단한 alert rule을 등록하여 발생한 alert을 slack으로 전달해주는 부분을 살펴보았습니다. Prometheus는 심플함과 손쉬운 사용성 등으로 인해 점차 많은 곳에서 사용되고 있고, TACO가 아닌 일반적인 클러스터 환경에서도 자유롭게 사용 가능한 Tool이므로, 각자 사용하시는 환경에 맞게 얼마든지 구성 및 다양한 응용이 가능할 것입니다. 아울러 Graphana 등 Graphical dashboard 연동을 통해 훌륭한 모니터링 환경을 제공할 수 있으므로 모니터링 tool을 고민 중이신 분들은 한번쯤 고려해보시면 좋을 것 같습니다.